
terraform-aws-arc-glue¶
Module:
sourcefuse/arc-glue/awsRegistry: https://registry.terraform.io/modules/sourcefuse/arc-glue/aws
Category: Analytics / ETL
Source: https://github.com/sourcefuse/terraform-aws-arc-glue
![]()
![]()
![]()
![]()
Tip
🤖 New: Use this module with AI assistants via the ARC IaC MCP Server — search, scaffold, and security-scan ARC modules from natural language. Quick setup ↓
Overview¶
Manages AWS Glue resources — data catalog databases, ETL jobs, crawlers, workflows, connections, and triggers — for data lake and ETL pipelines.
Architecture¶
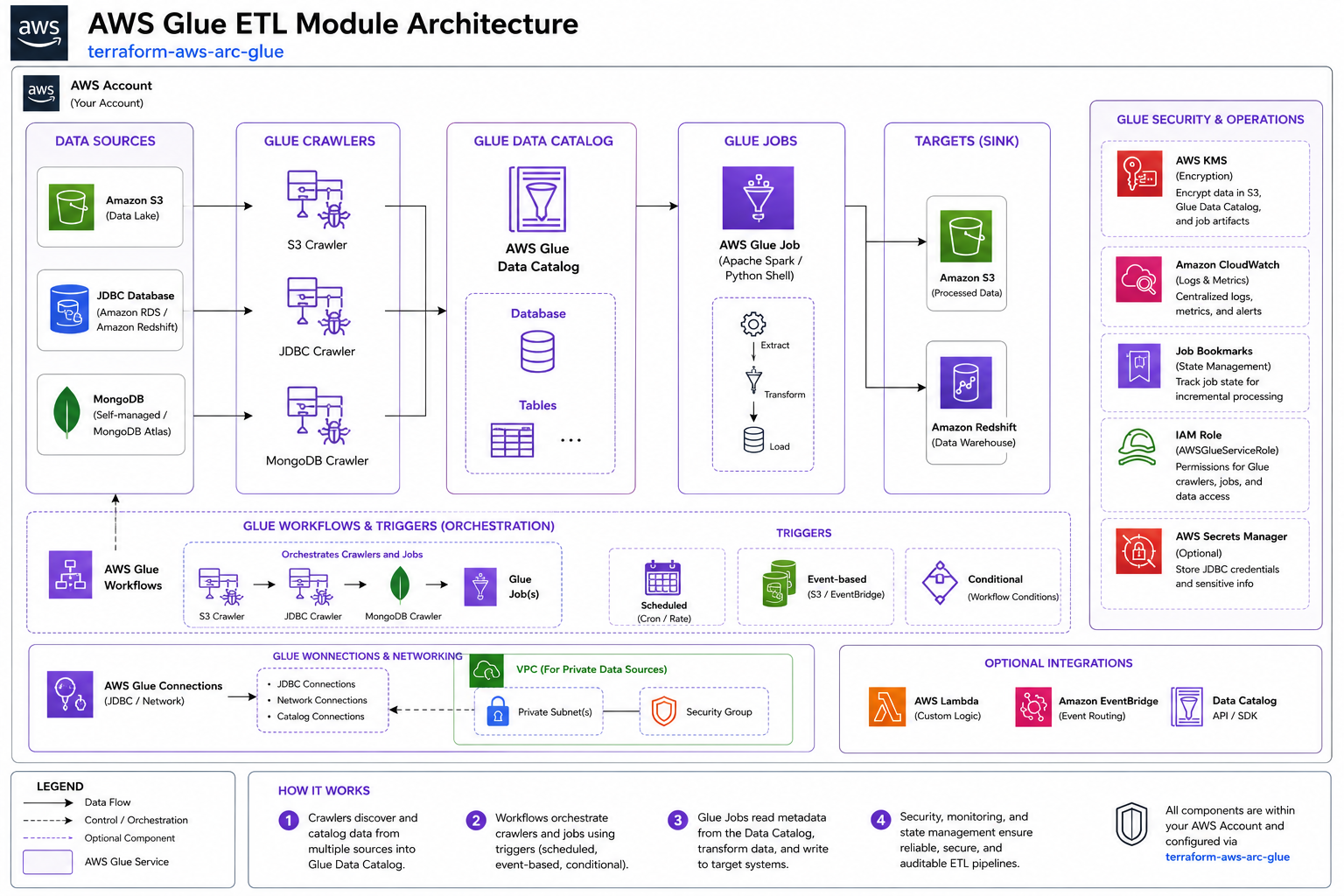
What It Does¶
- Glue Data Catalog databases and tables
- ETL jobs (Spark, Python Shell, Ray) with configurable workers
- Crawlers for automatic schema discovery from S3, JDBC, and more
- Workflows and triggers for orchestration
- Glue connections for JDBC and network sources
- IAM roles with least-privilege policies
- CloudWatch metrics and job bookmarks
For more information about this repository and its usage, please see Terraform AWS GLUE Usage Guide.
Quickstart¶
Required Inputs¶
| Name | Type | Description |
|---|---|---|
namespace |
string |
Namespace prefix |
environment |
string |
Deployment environment |
name |
string |
Component name |
region |
string |
AWS region |
| ## Key Outputs |
| Name | Description |
|---|---|
database_name |
Glue catalog database name |
job_names |
Map of Glue job names |
crawler_names |
Map of crawler names |
| ## Full Variable & Output Reference |
The complete inputs/outputs reference is auto-generated below.
Requirements¶
| Name | Version |
|---|---|
| terraform | >= 1.5.0 |
| aws | >= 5.0, < 7.0 |
Providers¶
| Name | Version |
|---|---|
| aws | 6.40.0 |
Modules¶
No modules.
Resources¶
| Name | Type |
|---|---|
| aws_glue_catalog_database.main | resource |
| aws_glue_classifier.csv | resource |
| aws_glue_classifier.grok | resource |
| aws_glue_classifier.json | resource |
| aws_glue_classifier.xml | resource |
| aws_glue_connection.main | resource |
| aws_glue_crawler.main | resource |
| aws_glue_job.main | resource |
| aws_glue_security_configuration.main | resource |
| aws_glue_trigger.main | resource |
| aws_glue_workflow.main | resource |
| aws_iam_role.glue | resource |
| aws_iam_role_policy_attachment.glue_basic | resource |
| aws_iam_role_policy_attachment.glue_custom | resource |
| aws_iam_role_policy_attachment.glue_s3 | resource |
| aws_secretsmanager_secret.main | resource |
| aws_secretsmanager_secret_version.main | resource |
| aws_caller_identity.current | data source |
| aws_iam_policy_document.assume_role | data source |
Inputs¶
| Name | Description | Type | Default | Required |
|---|---|---|---|---|
| environment | Environment identifier (e.g., dev, staging, prod) | string |
n/a | yes |
| glue_config | AWS Glue configuration | object({ |
{} |
no |
| glue_connections | Glue connections to create. Kept separate from glue_config to avoid for_each unknown value issues when connection_properties contain apply-time values. | map(object({ |
{} |
no |
| glue_crawlers | Glue crawlers. Kept separate from glue_config to avoid for_each unknown-value issues when targets contain apply-time values. | map(object({ |
{} |
no |
| glue_jobs | Glue jobs. Kept separate from glue_config to avoid for_each unknown-value issues when script_location contains apply-time values. | map(object({ |
{} |
no |
| iam_config | IAM configuration for Glue resources | object({ |
{} |
no |
| kms_key_arn | Optional KMS key ARN to use for Glue encryption. If not provided, module will create its own KMS key but won't use it for security configurations to avoid circular dependencies. | string |
null |
no |
| name | Name prefix for AWS Glue resources | string |
n/a | yes |
| namespace | Namespace (organization) identifier for resources | string |
n/a | yes |
| region | AWS region where resources will be created | string |
"us-east-1" |
no |
| secrets_config | Secrets Manager configuration for storing credentials | object({ |
{} |
no |
| tags | Default tags to apply to all resources | map(string) |
{} |
no |
Outputs¶
| Name | Description |
|---|---|
| aws_account_id | The AWS account ID where resources are created |
| glue_connection_names | Map of connection key to name |
| glue_crawler_arns | Map of crawler name to ARN |
| glue_crawler_names | Map of crawler key to name |
| glue_database_arn | The ARN of the Glue catalog database |
| glue_database_id | The ID of the Glue catalog database |
| glue_database_name | The name of the Glue catalog database |
| glue_iam_role_arn | The ARN of the Glue IAM role |
| glue_iam_role_id | The ID of the Glue IAM role |
| glue_iam_role_name | The name of the Glue IAM role |
| glue_job_arns | Map of job key to ARN |
| glue_job_names | Map of job key to name |
| glue_secret_arns | Map of secret key to ARN |
| glue_security_configurations | Map of security configuration key to name |
| glue_workflows | Map of workflow key to workflow object |
| module_version | The version of this module |
| resource_prefix | The resource prefix used for naming |
Examples¶
Simple Example¶
Basic configuration with database and S3 crawler:
Complete Example¶
Enterprise configuration with jobs, workflows, and connections:
Module Configuration Details¶
IAM Configuration¶
The module can create and manage IAM roles with appropriate permissions:
VPC Configuration¶
For private Glue jobs and connections:
Glue Job Types¶
The module supports multiple Glue job types:
Spark ETL Jobs:
Python Shell Jobs:
Workflow Orchestration¶
Complex workflow orchestration with triggers:
Security Considerations¶
Encryption¶
The module supports comprehensive encryption:
Network Security¶
- VPC Integration: Deploy Glue resources in private VPC subnets
- Security Groups: Control inbound/outbound traffic
- Endpoints: Use VPC endpoints for private connectivity
- IAM Policies: Implement least-privilege access
Troubleshooting¶
Common Issues¶
1. Crawler Timeout
2. Job Failures
- Check CloudWatch Logs: /aws-glue/jobs/output
- Verify IAM permissions: S3, CloudWatch, Glue
- Validate script locations in S3
- Review security group rules for network access
3. Connection Issues - Verify VPC endpoints for JDBC connections - Check security group ingress/egress rules - Validate credentials in Secrets Manager - Test connectivity from Glue to data source
Cost Optimization¶
Worker Type Selection¶
- Standard: Cost-effective for simple transformations
- G.1X: Memory-intensive workloads
- G.2X: Balanced compute/memory
- Z.2X: Compute-intensive with lower memory
Job Configuration¶
Best Practices¶
- Resource Naming: Use consistent, descriptive resource names
- Tagging Strategy: Implement comprehensive tagging for cost management
- Incremental Processing: Use job bookmarks for efficiency
- Testing: Test jobs in development environment before production
- Monitoring: Set up CloudWatch alarms and metrics
- Security: Regularly audit IAM permissions and security groups
- Version Control: Store Glue scripts in version control
- Documentation: Document job logic and data transformations
Development¶
Prerequisites¶
Configurations¶
- Configure pre-commit hooks
Versioning¶
while Contributing or doing git commit please specify the breaking change in your commit message whether its major,minor or patch
For Example
Tests¶
- Tests are available in
testdirectory - Configure the dependencies
- Now execute the test
AI Assistant Integration (ARC IaC MCP)¶
The ARC IaC MCP Server is a hosted Model Context Protocol service that lets AI assistants browse, search, scaffold, compare, and security-scan any of the SourceFuse ARC Terraform modules — directly from natural language.
What you can do with it:
- Discover — search and filter modules by keyword or AWS resource type.
- Understand — get inputs, outputs, and resources for any module without leaving your editor.
- Scaffold — generate production-ready, multi-file Terraform with cross-module wiring already done.
- Secure — scan generated or existing HCL for misconfigurations before it hits a PR.
- Compare — diff modules side-by-side to make informed architectural decisions.
Setup (one minute)¶
The MCP endpoint is https://arc-iac-mcp.sourcef.us/mcp. Pick your client:
Claude Code CLI:
Claude Desktop — edit ~/Library/Application Support/Claude/claude_desktop_config.json:
Cursor / Windsurf / Kiro — add the same block to .cursor/mcp.json (or the equivalent for your client).
Example prompts to try¶
- "List all ARC modules sorted by downloads"
- "What inputs does
arc-ecsrequire?" - "Scaffold a production-ready
arc-dbAurora setup with Secrets Manager" - "Compare
arc-eksandarc-ecsfor running 10 microservices" - "Scan this Terraform before I raise a PR:
<paste HCL>"
See the ARC IaC MCP repo for the full tool reference, troubleshooting tips, and local-development instructions.
Contributing¶
See CONTRIBUTING.md for commit conventions and development setup.
Authors¶
This project is authored by: - SourceFuse ARC Team